Instytut Badań Literackich został założony w 1948 r. jako instytut badawczy Polskiej Akademii Nauk. Głównym celem instytutu jest prowadzenie badań dotyczących historii polskiej literatury, teorii literatury, historii kultury oraz dokumentacji literackiej. Pracownikami instytutu są przede wszystkim wyspecjalizowani profesorowie, docenci i pracownicy naukowi. IBL uczestniczy w wielu międzynarodowych projektach naukowych. Jednym z nich jest program badawczo-naukowy pt. ,,Polskie dziedzictwo kulturowe w nowej Europie”. W ramach tego projektu IBL ściśle współpracuje z wieloma zagranicznymi ośrodkami kultury.

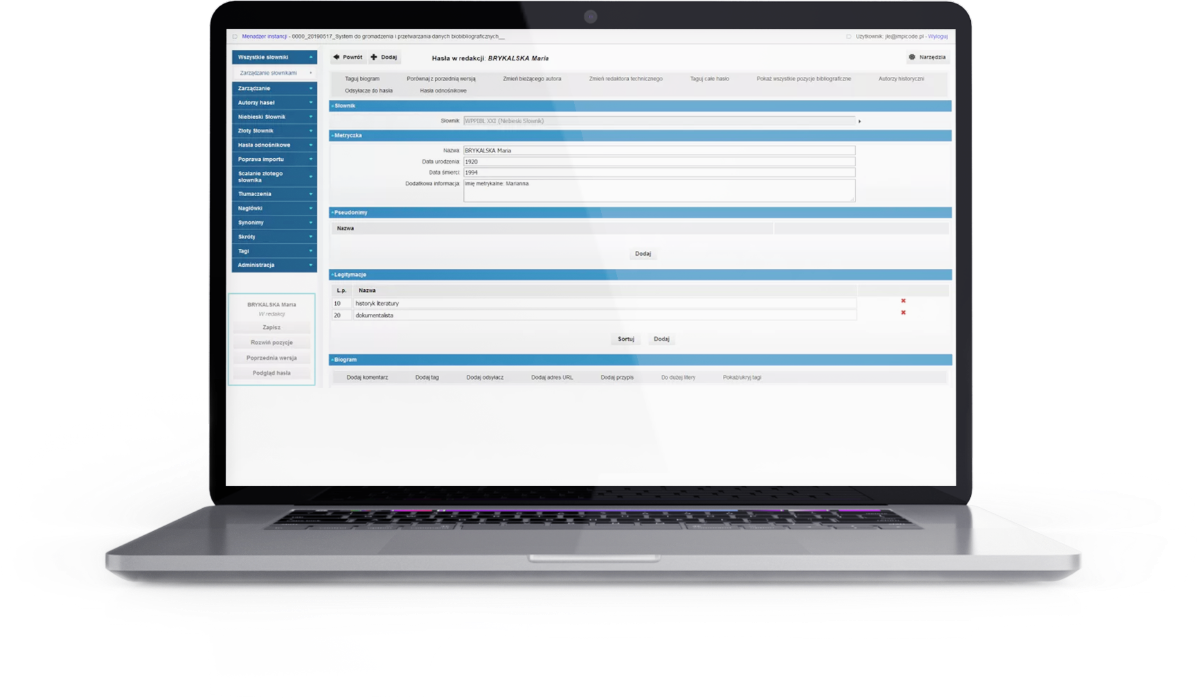
Instytut Badań Literackich PAN zwrócił się do nas z prośbą o stworzenie systemu umożliwiającego pracę zespołową nad tworzeniem i rozbudowywaniem słownika biobibliograficznego polskich pisarzy i badaczy literatury polskiej. Słownik stanowi zwieńczenie lat pracy wieloosobowego zespołu badawczego. IBL potrzebował narzędzia, które umożliwi im stałe śledzenie zmian wprowadzanych do słownika oraz dostarczy prosty i klarowny system przekazywania informacji między współpracownikami, a w dalszej perspektywie ułatwi badaczom literatury z całego świata dostęp do ogromnej bazy wiedzy na temat polskiej literatury.
W ramach zlecenia stworzyliśmy nowoczesny system przystosowany do specyfiki przetwarzania dużych danych tworzonych i edytowanych dotąd w języku naturalnym. Dogłębnie przeanalizowaliśmy potrzeby pracowników naukowych i zbudowaliśmy zaawansowany proces przepływu informacji między użytkownikami. Ponadto importowaliśmy i zintegrowaliśmy duże zbiory historycznych danych biobibliograficznych, uspójniając rekordy pochodzące z kilku źródeł wskazanych przez Klienta.

Jednym ze źródeł, które importowaliśmy, był dostępny online słownik „Polscy pisarze i badacze literatury przełomu XX i XXI wieku”. Treści zostały pobrane przy użyciu narzędzi do web scrapingu. Przeanalizowane i uporządkowane dane zostały przeniesione do stworzonego przez nas systemu. Wielkim atutem naszego rozwiązania było ustrukturyzowanie i uspójnienie słownika dzięki zastosowaniu narzędzi wymuszających trzymanie się ustalonej konwencji edytorskiej. Dzięki temu wszyscy członkowie zespołu korzystający z naszego rozwiązania pracują nad tekstami o ściśle określonej strukturze. Warto wspomnieć, że słownik naszego Klienta jest pod wieloma względami unikatowy, ponieważ oprócz podstawowych części biograficznych i bibliograficznych, zawiera także wybrane opracowania do dzieł autora jak również zbierane przez dziesięciolecia materiały pochodzące z korespondencji listownej z pisarzami.
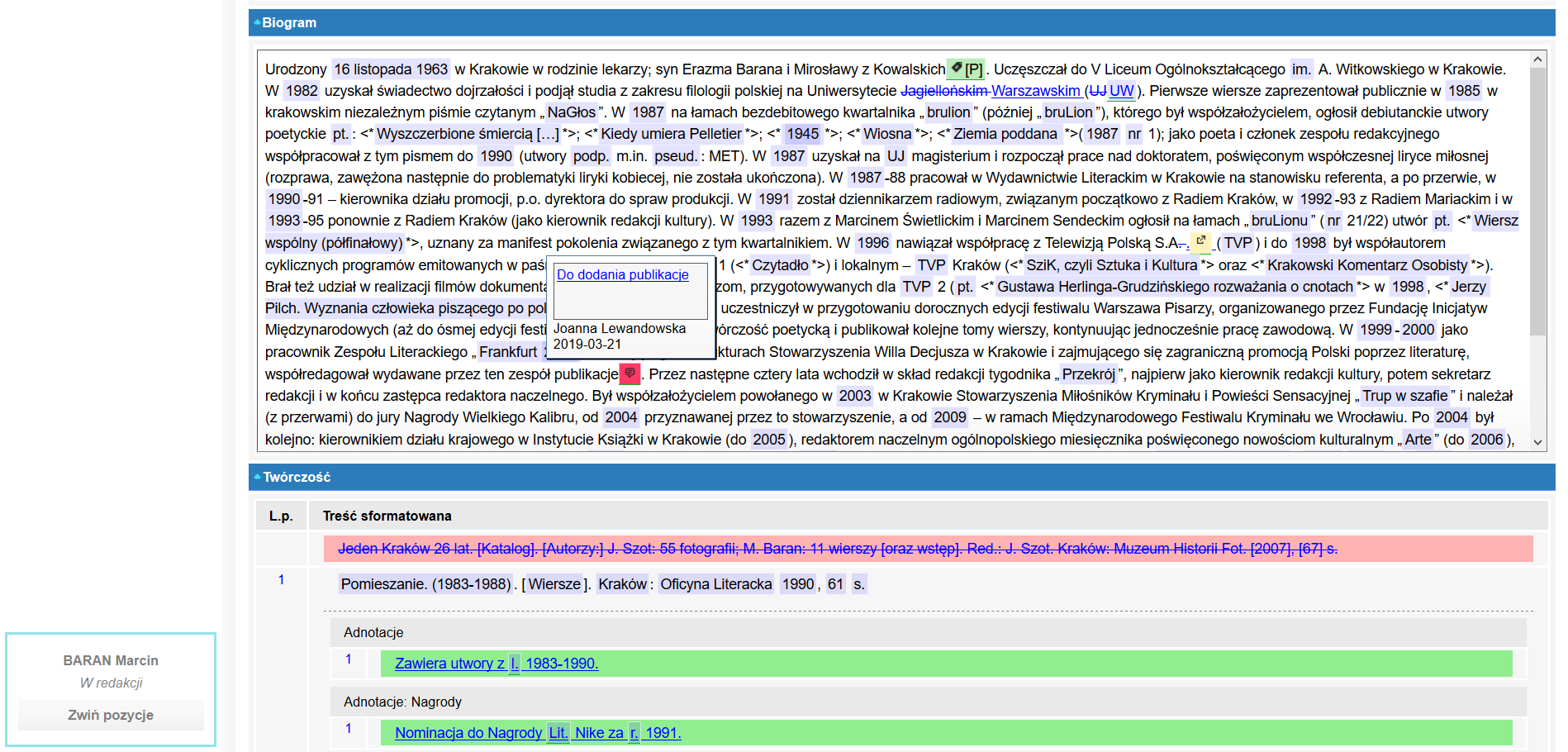
Zbudowaliśmy platformę umożliwiającą wyświetlanie, wprowadzanie i zarządzanie danymi. Chcąc zbudowawać profesjonalne narzędzie dla naszego Klienta, musieliśmy dodać do platformy wiele wtyczek, które umożliwiły wyświetlanie dodatkowych paneli i informacji. IBL jest bardzo zadowolony ze stworzonego specjalnie na potrzeby projektu edytora tekstu WYSIWYG, który ułatwia pracownikom naukowym tworzenie haseł i treści. Dzięki naszemu systemowi pracownicy IBL-u mają możliwość intuicyjnego wyszukiwania i analizy informacji. W ten sposób system stał się także narzędziem do analizy danych. Warto podkreślić, że funkcjonalność wyszukiwania została wzbogacona poprzez zastosowanie opracowanego specjalnie dla tego projektu autorskiego algorytmu tagowania.
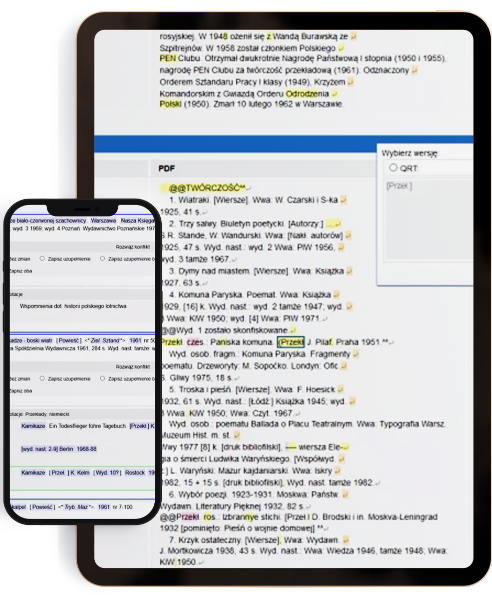
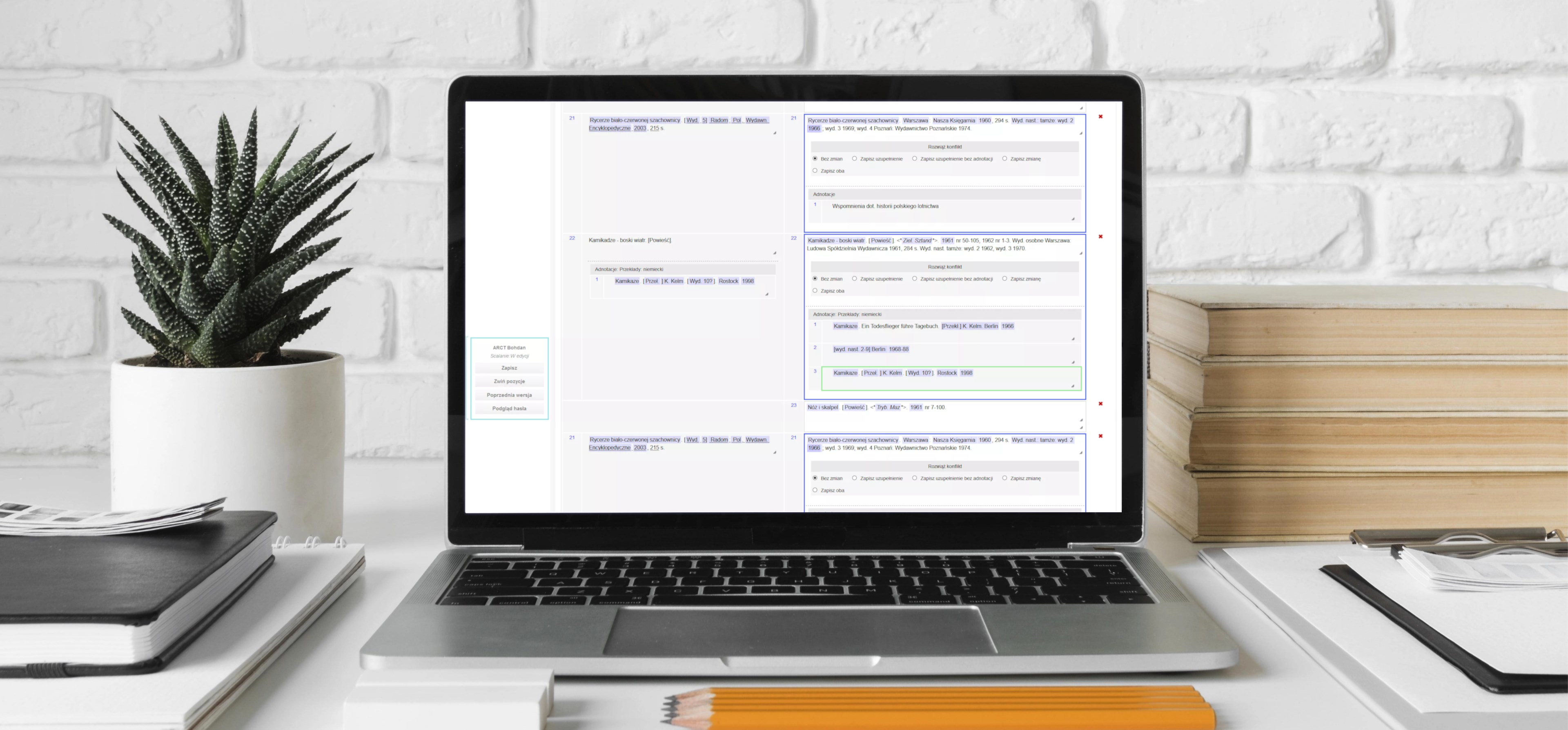
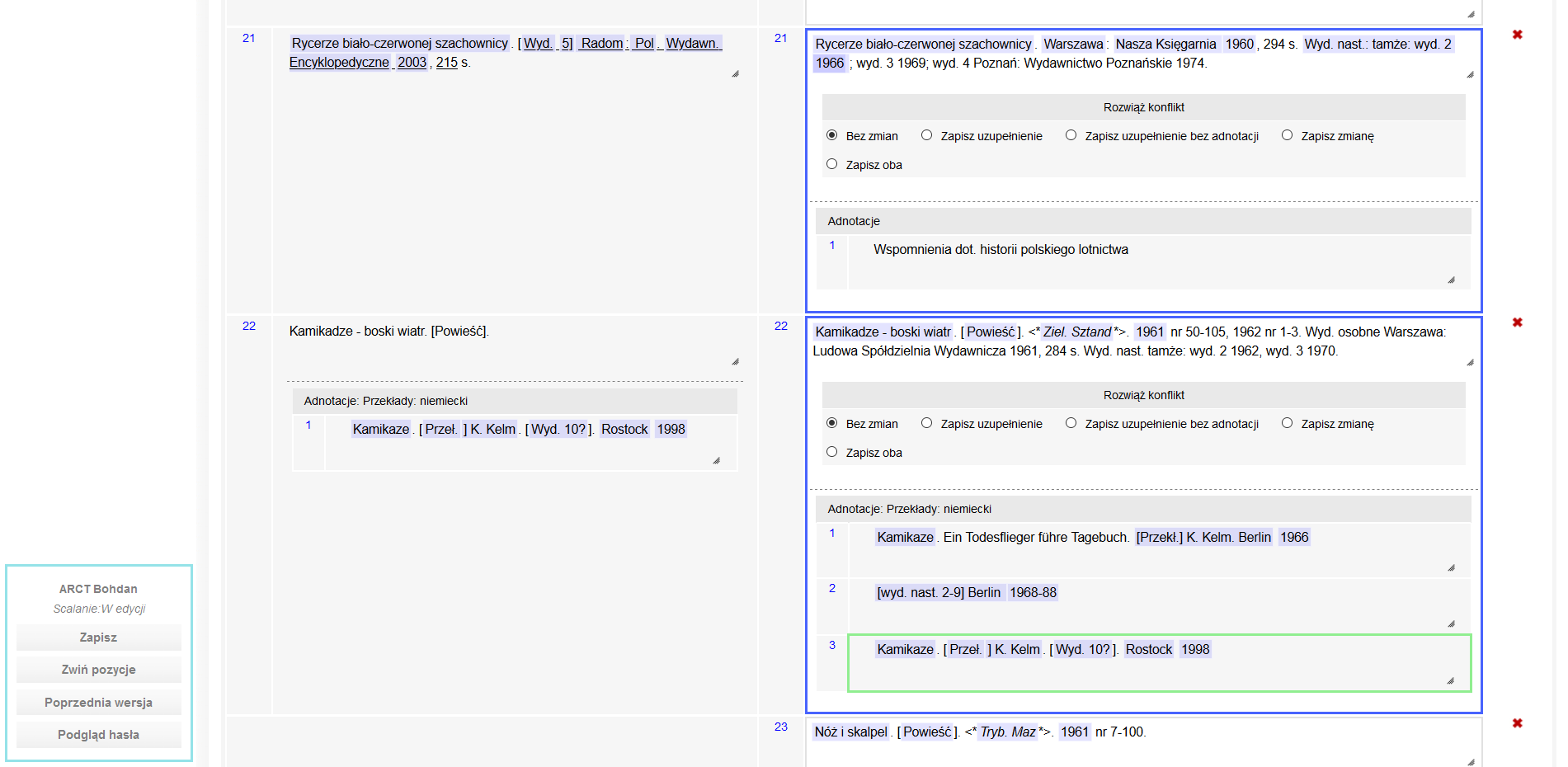
Jednym z nietypowych wyzwań, na które natknęliśmy się podczas realizacji zlecenia dla IBL-u, był import 10-tomowego słownika w formacie PDF do systemu. Słownik został poddany analizie OCR służącej do rozpoznawania tekstu. Dostaliśmy również dostęp do wersji roboczej tego samego słownika w formacie QRT. Jednak z powodu licznych błędów występujących w dokumentacji zarówno w wersji PDF jak i QRT, musieliśmy zastosować autorską heurystykę, która pozwoliła nam na scalenie haseł z obu źródeł. Podczas procesu scalania haseł korzystaliśmy z przygotowanej przez nas statystyki różnic występujących między źródłami. Warto wspomnieć, że dziesiąty tom słownika zawierał uzupełnienia do haseł występujących w dziewięciu poprzednich tomach, dlatego też do naszego systemu wprowadziliśmy funkcję, która umożliwia wyświetlanie panelu uzupełnień i pokazuje o jaką pozycję dane hasło zostało uzupełnione.
Zgodnie z wymaganiami Klienta dodaliśmy do systemu dodatkowy panel wykorzystywany przez tłumaczy. Panel jest w pełni zintegrowany z polskimi hasłami. W momencie wprowadzenia zmiany w polskim słowniku, tłumacz automatycznie dostaje informację o tym, w którym haśle i w jakiej pozycji dokonano zmiany i od razu może wprowadzić poprawkę do angielskiej wersji słownika. W ten sposób proces komunikacji między pracownikami naukowymi, a tłumaczami został znacznie usprawniony.




Dalszy rozwój cyfrowego słownika
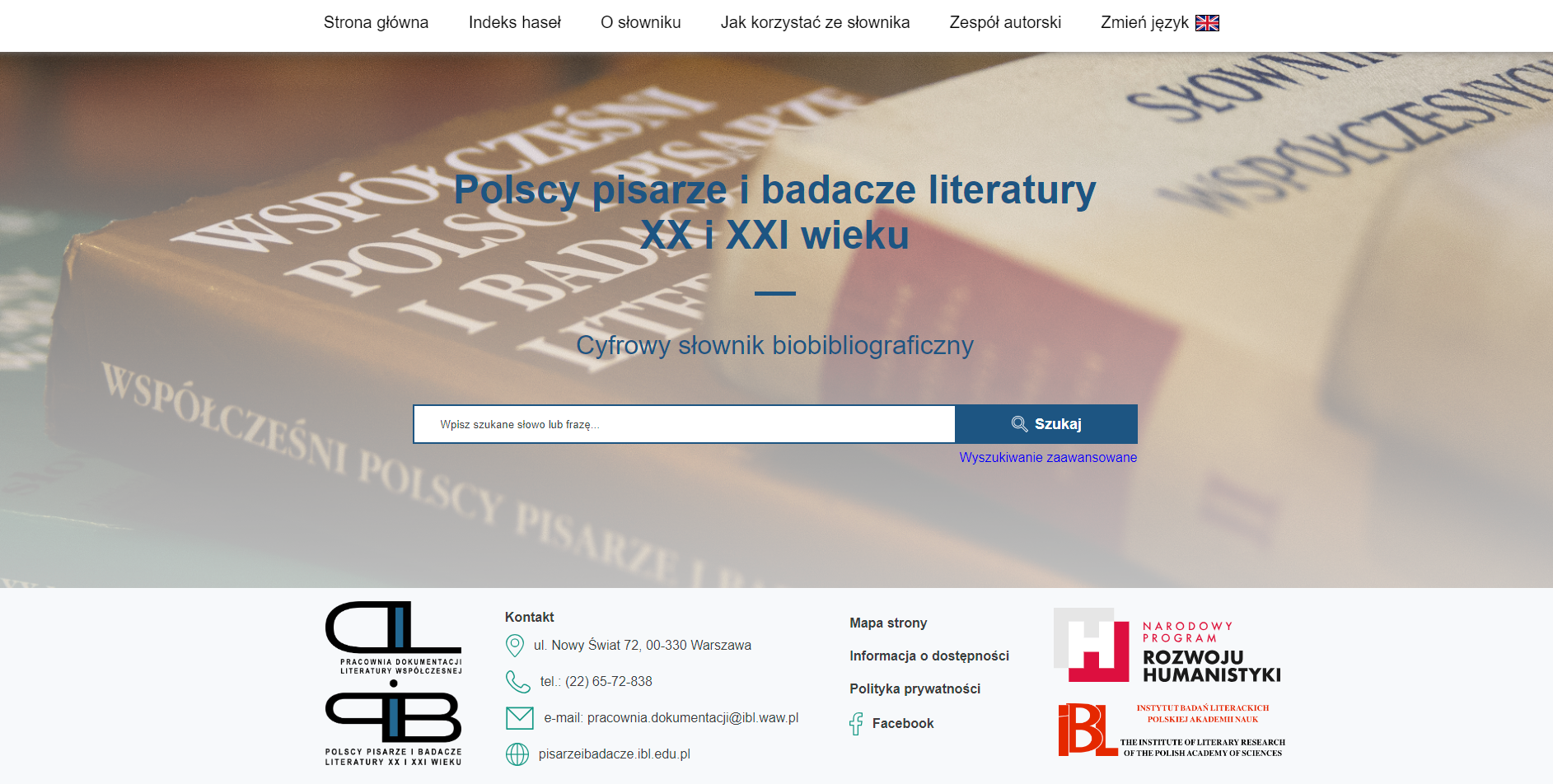
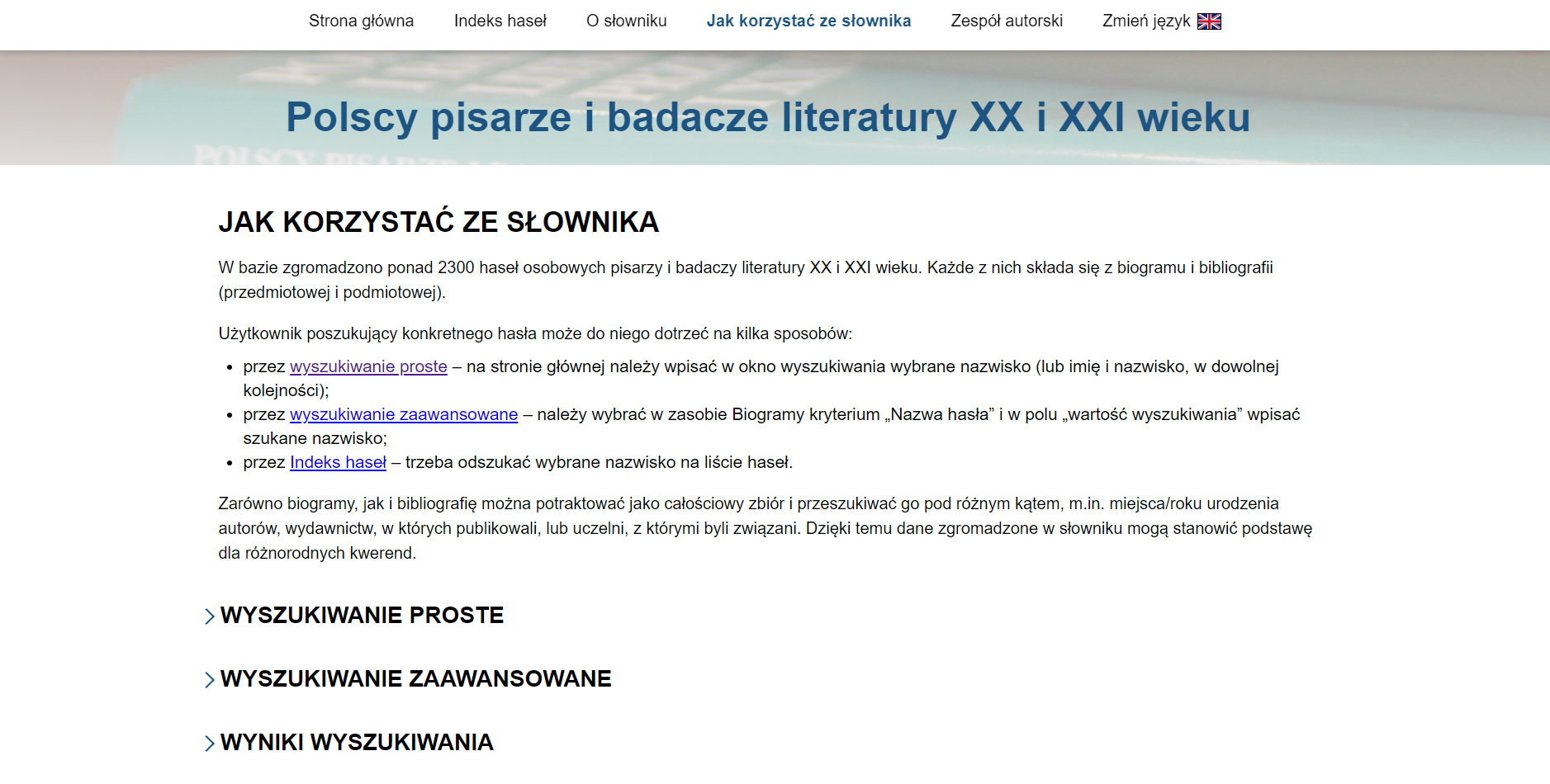
Po pozytywnym odbiorze pierwszej wersji aplikacji podjęliśmy się z Instytutem Badań Literackich dalszego rozwoju oprogramowania. Prace głównie skupiały się nad stworzeniem interfejsu dla użytkownika zewnętrznego. Aktualnie z cyfrowego słownika biobibliograficznego “Polscy pisarze i badacze literatury XX i XXI wieku” może korzystać każdy, nawet niezalogowany użytkownik.
Zawiera hasła około 2300 autorów, którzy rozwinęli działalność po 1918 r. w kraju i na emigracji. Słownik przeznaczony jest dla badaczy różnych dziedzin, a także dla studentów, nauczycieli i szerokiego grona czytelników poszukujących w Internecie rzetelnych informacji. Warto zaznaczyć, że cyfrowy słownik zastępuje wydawany przez wiele lat przez Instytut Badań Literackich wielotomowy słownik w wersji papierowej.


Dzięki naszemu rozwiązaniu efektywność prac redakcyjnych pracowników naukowych IBL-u znacznie wzrosła. Firma ImpiCode zaimportowała i zintegrowała duże zbiory biobibliograficzne, dzięki czemu pracownicy IBL-u uniknęli wielomiesięcznej pracy polegającej na ręcznym przepisywaniu słowników. Dodatkowo Klient uzyskał narzędzie umożliwiające zaawansowane zarządzanie danymi. O zadowoleniu z otrzymanego rozwiązania i przebiegu współpracy świadczą udzielone referencje.

ImpiCode managed the project well, adhering to the budget and taking scope changes in stride. The responsive and patient team provided actionable suggestions. Management and executives were communicative and readily available.
Inne nasze realizacje













Zaufali nam:
![]()
![]()
Polski Związek Motorowy
![]()
![]()
Adamed
![]()
![]()
Polska Agencja Prasowa
![]()
![]()
Astor
![]()
![]()
IFX Payments
![]()
![]() TEB Edukacja
TEB Edukacja
![]()
![]() Fundacja Moc Pomocy
Fundacja Moc Pomocy
![]()
![]() Elemental Holding
Elemental Holding
![]()
![]() French Touch
French Touch
![]()
![]()
Polski Komitet Normalizacyjny
![]()
![]()
TU
Bergakademie Freiberg
![]()
![]()
Bank Nowy BFG
![]()
![]()
Narodowe Centrum Promieniowania Synchrotronowego SOLARIS
![]()
![]()
Astorino Kawasaki Robotics
![]()
![]()
DTK&W Zespół Ogłoszeniowy
![]()
![]()
Opegieka
![]()
![]()
Crazy shop
![]()
![]()
PartyBox
![]()
![]()
WUOZ w Krakowie
![]()
![]()
Uniwersytet Medyczny w Łodzi
![]()
![]()
Grupa Mo
![]()
![]()
Jeleniogórska Organizacja Turystyczna
![]()
![]()
eFitness
![]()
![]()
Instytut Badań Literackich PAN
![]()
![]()
Danhoss
![]()
![]()
Fundacja Sztuki, Przygody i Przyjemności ARTS
![]()
![]()
Opennet.pl
![]()
![]()
Centrum Medyczne Intermed
![]()
![]()
Centrum Rozwoju Edukacji Edicon
![]()
![]()
Winner Europe
![]()
![]()
Po amputacji
![]()
![]()
MamMoc.pl
![]()
![]()
EtnoStoria
![]()
![]()
Widzisz Wszystko
![]()
![]()
EMKA Project
![]()
![]()
NowaLed ILL
![]()
![]()
Eco Light LED
![]()
![]()
LoxiMide
![]()
![]()
Fundacja AVLab.pl
![]()
![]()
RCC Nova
![]()
![]()
Vector Controls
![]()
![]()
Virtual SMS
![]()
![]()
Parus Holdings
![]()
![]()
Biuro Partner
![]()
![]()
Optime.AI
![]()
![]()
M2M Team